Tier-1 broadcasters: hardware encoding vs cloud software
More live video workflow notes and product updates.

Written by Iurii Pakholkov
Founder of Callaba. Building cloud video tools for SRT, RTMP, WebRTC, NDI, live routing, monitoring, recording, and production workflows.
For tier-1 live operations, the useful question is not whether hardware encoding or cloud software is better in every case. The useful question is where each function should live: at the venue, in a managed IP plant, in cloud ingest, in production, or near distribution.
Quick answer
Tier-1 broadcasters usually land on hybrid architecture: keep physical capture, timing-sensitive switching, and first-mile encoding close to the source when needed; use cloud software for ingest control, monitoring, recording, failover, transcoding, remote access, and distribution fan-out when the latency, network, security, and support model have been tested.
Decision path
- 1. Source and I/O
- 2. First encode
- 3. Contribution
- 4. Cloud ingest
- 5. Monitor and recover
Move only the functions that your latency budget, network path, operations team, and failover plan can support under rehearsal conditions.
What this question really asks
Hardware encoders, on-prem software encoders, managed cloud encoders, and workflow platforms solve different parts of the live chain. A hardware appliance with SDI or HDMI inputs may be the right first-mile encoder. An on-prem VM encoder may fit a controlled data-center workflow. A cloud service may be better for burst events, fast channel creation, remote control, and downstream processing.
EBU cloud production guidance makes the same practical point: connectivity choices for real-time cloud production have to be tested against latency, reliability, security, and bandwidth requirements. It also frames ST 2110 and NMOS as strong foundations for time-sensitive on-site IP facilities, while noting that uncompressed HD and UHD bitrates can make cloud workflows impractical without mezzanine compression.
The practical answer
For high-stakes events, I normally start with this split:
- Use hardware or controlled on-prem software for physical inputs, deterministic timing, dense 24/7 channels, local recording, and first-mile encode where venue failure would be expensive.
- Use cloud software for elastic ingest, central monitoring, backup paths, remote production tooling, transcoding, recording copies, partner handoff, and OTT distribution preparation.
- Use hybrid control when the event needs venue-side certainty and cloud-side visibility.
Decision framework
| Workflow stage | Often keep near the venue | Often move to cloud/software | Main test |
|---|---|---|---|
| Capture and timing | Cameras, SDI/HDMI, ST 2110 plant, PTP domain | Remote control surfaces where proven | Reference timing, operator delay, rollback |
| First-mile encode | Dedicated encoder, on-prem VM, local record | Software encoder where compute and I/O are controlled | 24+ hour stability, drift, heat, audio mapping |
| Contribution | Diverse uplinks and backup encoder | SRT/RIST-style contribution to cloud receivers | Packet loss, RTT, jitter buffer, failover |
| Processing and distribution | Critical playout if required locally | Transcode, ABR packaging, HLS, DASH, CMAF, monitoring | Output compatibility, egress, CDN behavior |
Examples often evaluated in this category
| Vendor family | Often evaluated for | Typical deployment spot | Check carefully |
|---|---|---|---|
| Dedicated encoder appliances | Physical SDI/HDMI, dense channels, low-touch operation | Venue, truck, headend | Codec profiles, power and heat, support region, failover behavior |
| AWS Elemental Live | On-prem encoding on hardware or virtual machines | Headend, data center, controlled edge | Input/output formats, licensing, orchestration, long-run tests |
| AWS Elemental MediaLive | Cloud live processing and managed high-availability channel designs | Cloud ingest and transcoding | Standard channel design, input failover, region plan, egress cost |
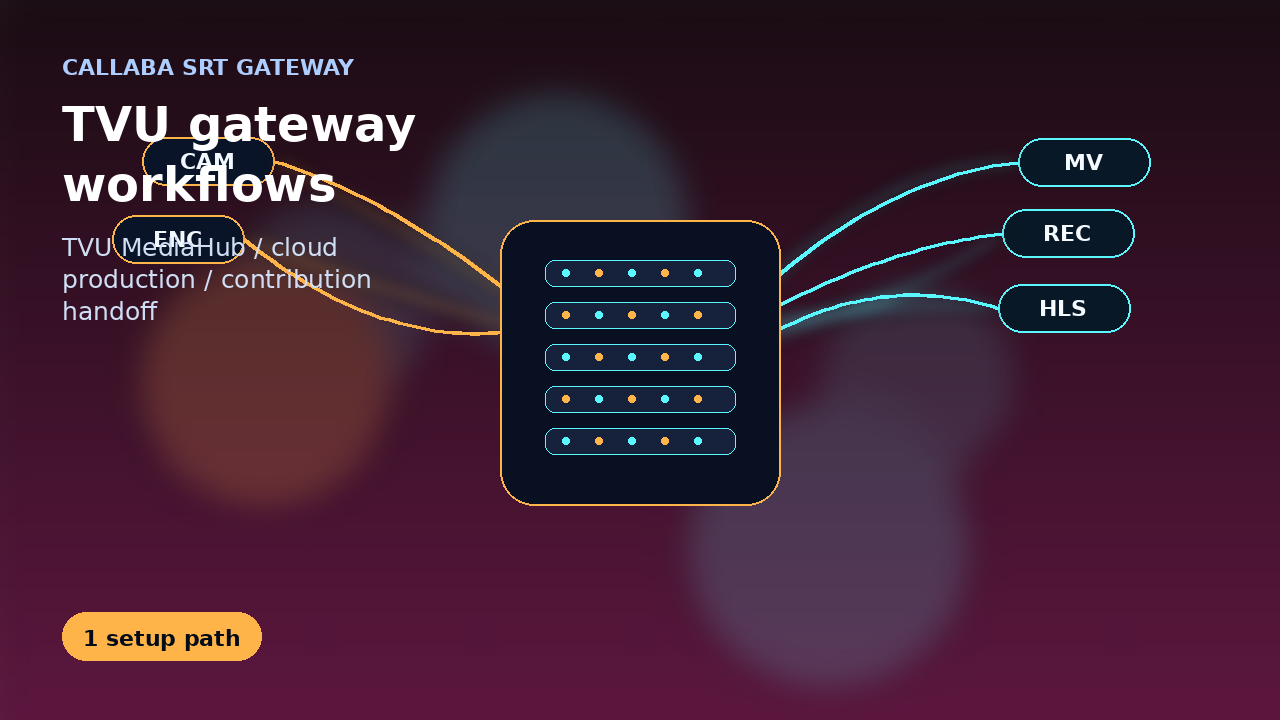
| Callaba | Cloud/self-hosted live video workflow platform for SRT/RTMP/WebRTC/NDI-oriented ingest, receiving, preview, recording, routing, restreaming, multiview, API workflows, failover, and downstream checks | Cloud, private cloud, self-hosted workflow layer | Not a physical SDI/HDMI capture encoder appliance; pair it with cameras, capture cards, or hardware encoders when physical inputs are needed |
Where Callaba fits
Where Callaba belongs in this comparison
Callaba is a direct option when the requirement is cloud or self-hosted live ingest, monitoring, recording, routing, restreaming, multiview, failover, and API-driven workflow control. It is an adjacent workflow layer when the RFP is strictly about physical SDI/HDMI capture, ASIC encoding, ASI, ST 2110 hardware I/O, or chassis-level headend features.
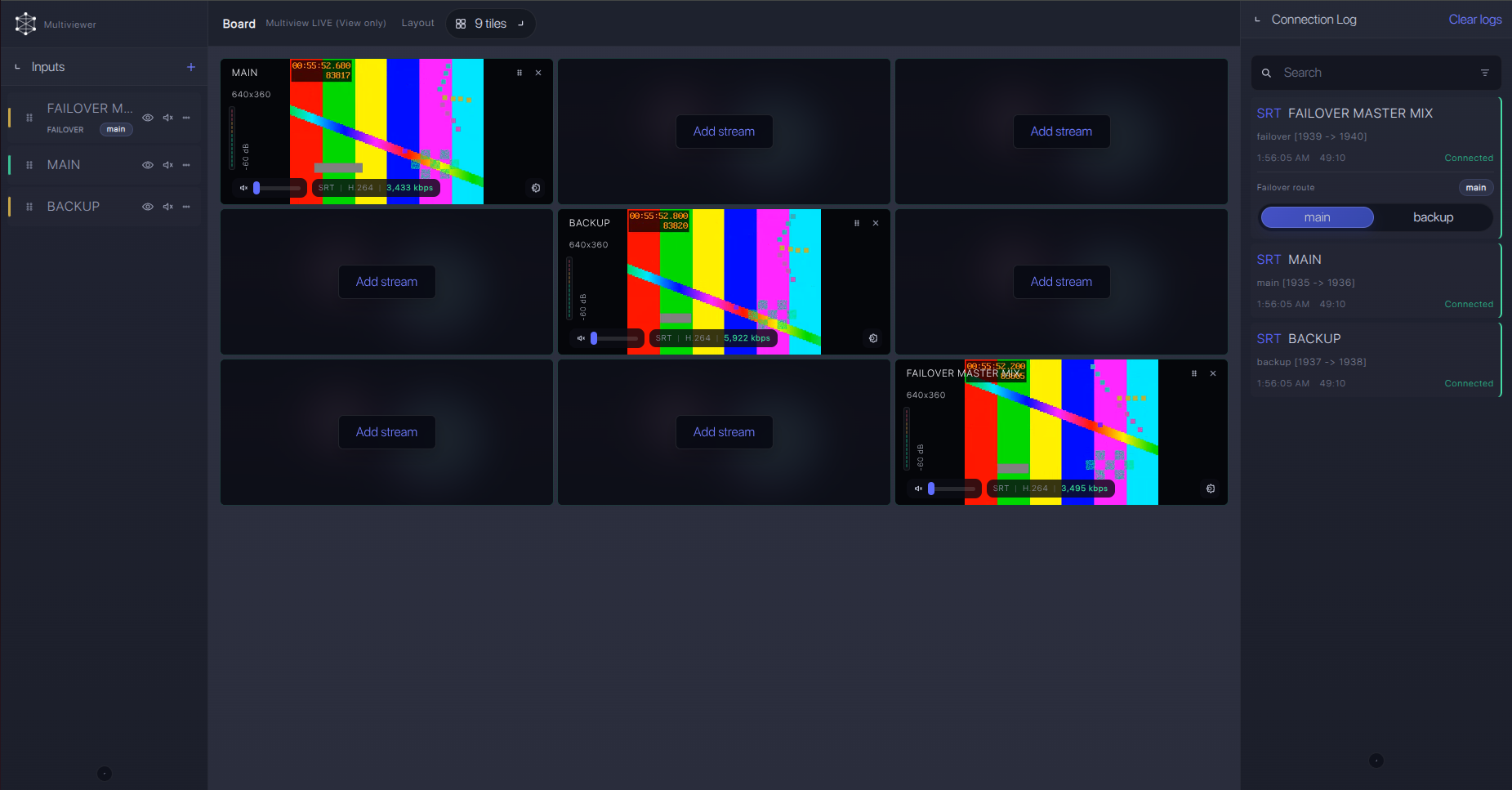
A common pattern is: venue encoder sends SRT to Callaba, operators preview the main and backup feeds, record the clean feed, route or restream outputs, and keep a prepared failover path. If the RFP also requires RIST, test that with a confirmed RIST receiver; do not assume any platform supports a protocol until the exact product documentation says so.
Implementation checks
Use this table as a compact RFP checklist. It covers more than codec names because tier-1 failures usually come from timing, operations, packaging, support, or recovery assumptions.
| Requirement | What to ask the vendor | How to test it | Where Callaba can help |
|---|---|---|---|
| PTP and reference timing | What happens on grandmaster failover? | Force timing changes during live encode | Observe contribution continuity after the encoder output changes |
| PCR/PTS stability | What are long-run jitter and drift limits? | Run 24+ hours with TS analysis | Record and monitor long feeds for comparison |
| ST 2110/NMOS | Which IS-04/IS-05 registry workflows are supported? | Join the test registry and verify SDP and routing | Use Callaba after the gateway or encoder output, not as the ST 2110 plant |
| Power and heat | Watts per channel at final codec profile? | Measure under redundant output load | Compare cloud receiver load separately from encoder density |
| ASI/IP ingest buffering | How does input-buffer overflow behave? | Apply burst and loss conditions | Check downstream stream recovery and recording impact |
| Output packaging | TS over IP, HLS, DASH, CMAF/fMP4, LL-HLS, LL-DASH, or elementary streams? | Send every required output to the real packager/origin | Receive, restream, and compare SRT/RTMP/WebRTC-oriented paths |
| Audio | AAC-LC, HE-AAC, Dolby Digital, Dolby Digital Plus, AC-4, MPEG-H, channel count, Dolby E/D pass-through, BS.1770 loudness? | Test mapping, pass-through, loudness, and failover audio | Preview, record, and verify the contribution copy |
| Security | BISS-CA, AES where applicable, HTTPS/TLS APIs, certificates, roles, audit logs? | Review management-plane access and rotate credentials | Use protected ingest endpoints and API-controlled operations |
| Cloud readiness | SRT/RIST output, API orchestration, disaster recovery, cloud-burst plan? | Rehearse primary and backup paths | Receive SRT, monitor, record, route, and fail over tested feeds |
| Regional support | Local engineering, escalation, spares, SLA response? | Open a test ticket before purchase | Document receiver-side evidence during escalation |
Latency budget and measurement
Measure the chain in parts: camera/source to processing, encoding, network, jitter buffer, decoding, and display or playout. Contribution latency is not the same as OTT viewer latency. A cloud-internal figure is also not the same as venue-to-cloud-to-viewer latency; for example, AWS describes Cloud Digital Interface as cloud-internal uncompressed live video transport with network latency as low as 8 ms inside compatible AWS workflows.
Use embedded counters, glass-to-glass measurements, transport-stream analyzers, PCR/PTS jitter checks, and long-run drift tests. For subjective quality, combine visual review with metrics such as VMAF or PSNR when they match your content type. A sports feed, concert feed, and low-motion studio feed can stress encoders differently.
How to run a fair bake-off
- Use the same source material, network conditions, GOP, bitrate ladder, audio layout, and output targets.
- Include operations staff, not only engineering management.
- Run 24+ hour soak tests and deliberate failover tests.
- Test APIs, monitoring, certificate rotation, user roles, and rollback.
- Write pass/fail criteria before the vendor demo.
In a regional multiplex bake-off, a team might discover that a channel-density claim changes when 4:2:2 10-bit, redundant outputs, and loudness processing are enabled. That is exactly why the test profile must match the real channel.
Common mistakes
- Assuming cloud automatically lowers cost without counting egress, redundancy, rehearsals, support, and staffing.
- Treating ST 2110/NMOS as public-internet contribution. It is for engineered managed IP media networks.
- Forgetting that dual-role appliances can encode, decode, route, gateway, or monitor; define failure domains by role, not only by box.
- Leaving audio, SCTE markers, certificates, or regional support until the final week.
Mini glossary
- PTP
- Precision Time Protocol used for timing in managed IP media systems.
- NMOS
- AMWA APIs for discovery, registration, and connection management in IP media systems.
- PCR/PTS
- Transport-stream timing fields used to track jitter, sync, and drift.
- CMAF
- Common Media Application Format, often used with fragmented MP4 packaging.
- VMAF/PSNR
- Objective quality metrics that can support, but not replace, operator review.
- BISS-CA
- Conditional-access scrambling used in some professional contribution workflows.
References
Sources used in this comparison
- EBU cloud production articles support the latency, interconnect, SRT interoperability, mix-minus, and operational-caveat discussion.
- SMPTE and AMWA sources support the ST 2110 and NMOS managed-IP facility context.
- AWS Elemental Live documentation supports the point that on-prem encoding can be hardware-based or virtualized.
- AWS MediaLive documentation supports the cloud live-processing and deliberate high-availability design discussion.
- AWS CDI documentation supports the cloud-internal latency caveat.
- Haivision’s vendor-published survey is useful market context, but I treat it as survey evidence rather than universal adoption proof.
FAQ
Are tier-1 broadcasters replacing hardware encoders with cloud software?
Not as a blanket rule. Many workflows are hybrid: hardware or controlled on-prem systems at the source, cloud software for ingest, monitoring, processing, recovery, and distribution tasks.
Is hardware encoding always more reliable?
No. Reliability depends on the full design: power, cooling, network diversity, encoder redundancy, cloud region planning, monitoring, support, and operator drills.
Is cloud encoding always cheaper?
No. Cloud can be efficient for burst and remote workflows, but cost depends on compute, managed-service fees, egress, redundancy, rehearsals, and staffing.
Where should SRT fit in this architecture?
SRT is commonly useful as a contribution path from venue encoders to cloud or self-hosted receivers. Confirm caller/listener direction, Stream ID, passphrase, latency, and codec settings before the event.
Can Callaba replace a physical encoder?
No. Callaba can receive and operate on the live stream; the camera, capture card, hardware encoder, or appliance still provides the physical input and initial encode when needed.
What is the first test I should run?
Run the real output profile for at least 24 hours, then force input loss, uplink loss, encoder failover, and cloud receiver failover while monitoring audio, timing, and recordings.
Next steps
Start by drawing the failure domains: venue capture, first encoder, contribution links, cloud receiver, production path, recording, distribution, and rollback. Then test the same program feed through every candidate path.
If you need a reliable receiver for a bake-off, spin up Callaba Cloud and test encoder feeds before the vendor decision.
Test hardware encoder output with Callaba
Use Callaba to receive SRT from hardware encoders, preview the feed, record it, route it, restream it, and validate downstream compatibility before committing the workflow to production.
Failover and local ingest options
For production events, plan what happens if the main encoder, venue uplink, or primary contribution path fails. Callaba can be part of that continuity plan without changing the basic Tier-1 broadcasters hardware encoding vs cloud software ingest workflow.