What Is Obs
More live video workflow notes and product updates.
What is OBS in production terms is a better question than what OBS is in general. OBS is an open broadcaster application, but in real systems it acts as a contribution endpoint whose stability depends on profile policy, scene discipline, and upstream routing design. This guide explains OBS from an engineering operations perspective. For this workflow, Player & embed is the most direct fit. Before full production rollout, run a Test and QA pass with Generate test videos and streaming quality check and video preview. For this workflow, Paywall & access is the most direct fit. Before full production rollout, run a Test and QA pass with a test app for end-to-end validation.
What this article solves
Teams often treat OBS as a complete streaming platform, then face reliability issues when audience scale grows or destination requirements multiply. OBS is excellent for capture and contribution encode, but production success requires separating these responsibilities from distribution, playback, and access management.
OBS role in a modern streaming stack
- Source aggregation: camera, screen, audio inputs, and overlays.
- Scene composition and switching.
- Primary encode with policy-controlled settings.
- Contribution output to routing infrastructure.
Everything after contribution should be handled by downstream services for scale and control.
Why teams choose OBS
- Broad hardware and source compatibility.
- Flexible scene system for live production.
- Strong community ecosystem and operator familiarity.
- Low barrier to initial deployment and fast prototyping.
Where OBS alone is not enough
- Multi-destination fault isolation.
- Access control and monetization flows.
- Large-scale playback analytics and ABR packaging.
- Automated provisioning across many recurring events.
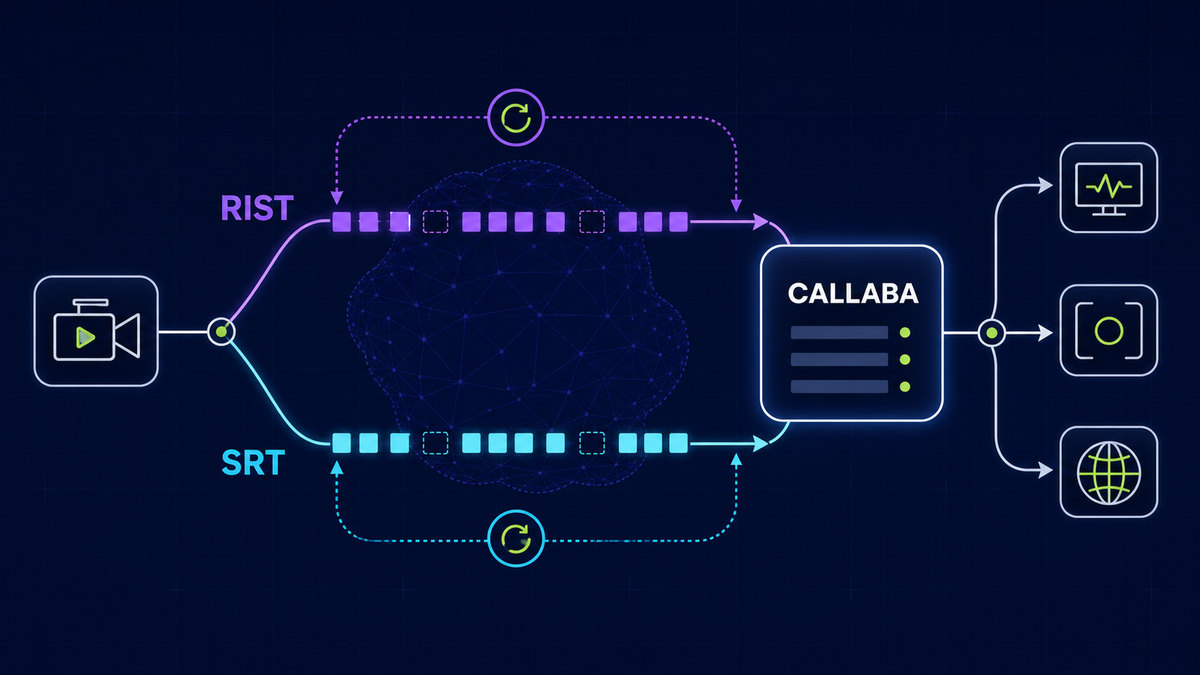
Production architecture with OBS
Use OBS for contribution, then pass stream input to a routing layer that handles fanout and resilience. Feed playback sessions through a managed player path where buffering, authentication, and metrics are controlled. Keep recording and VOD publishing independent from live operator actions.
Configuration policy for predictable OBS behavior
- One approved profile per content class.
- Locked frame rate and keyframe interval policy.
- Bitrate ceilings based on measured uplink availability.
- Audio normalization standards with verification checks.
- Scene template versioning and release notes.
Monitoring signals that matter
Track dropped frames, encode lag, RTT trends, packet loss, and destination publish errors. Combine ingest telemetry with playback metrics so support tickets can be mapped to root causes quickly. Without this feedback loop, teams repeat the same incidents across events.
Typical anti-patterns
- Anti-pattern: manual tweaks in the final minutes before live.
Fix: freeze profile and scene changes before event window. - Anti-pattern: one OBS output directly to many platforms.
Fix: send one stable contribution stream to routing infrastructure. - Anti-pattern: no backup path strategy.
Fix: pre-validate secondary path and failover procedure.
Product mapping
For complete implementation, pair OBS workflows with Ingest and route, 24/7 streaming channels, and Video platform API. For interactive sessions, use Calls and webinars.
Migration path from OBS-only setup
- Keep OBS for source and contribution where operators are already efficient.
- Move destination fanout to a dedicated routing layer.
- Add player and access control services for session quality and policy enforcement.
- Automate event provisioning and profile checks via API.
Run migration in phases instead of one hard cutover. Start by preserving current operator workflow in OBS while moving only fanout and recording out of the desktop environment. This delivers immediate reliability gains with low change risk.
After that, introduce policy checks before every publish event. Enforce profile compliance, source readiness, and destination health validation. Teams that add these checks usually reduce repeat incidents much faster than teams that only tune encoder parameters.
Related practical guides
See OBS live operations, OBS streaming checklist, RTMP fundamentals, and how to stream in production.