Obs Streaming
More live video workflow notes and product updates.
OBS streaming can be reliable at production scale, but only when you treat OBS as one controlled component in a larger delivery system. This guide explains how to run OBS with repeatable profiles, stable ingest, and measurable output quality for teams that need predictable live operations. For this workflow, Paywall & access is the most direct fit. Before full production rollout, run a Test and QA pass with Generate test videos and streaming quality check and video preview. Before full production rollout, run a Test and QA pass with a test app for end-to-end validation.
What this article solves
Many teams start with OBS defaults, then hit random failures during high-traffic broadcasts: dropped frames, unstable bitrate, drift in audio-video sync, and inconsistent quality across destinations. The root cause is usually not OBS alone. The problem is missing operational standards around network path, encoder policy, and monitoring.
Production architecture for OBS
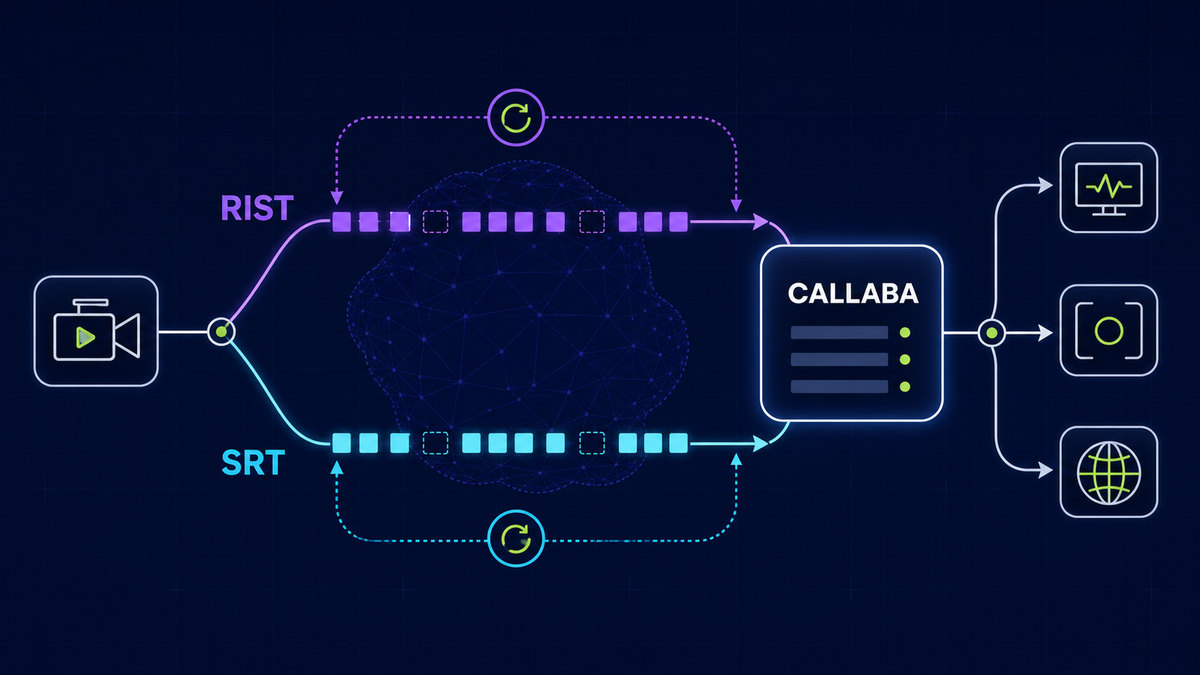
A resilient topology separates contribution from distribution. Use OBS for contribution ingest, then let your platform handle fanout, recording, adaptive playback, and access controls. This keeps OBS focused on source capture and initial encode while reducing blast radius when one destination fails.
- Source and scene management in OBS.
- Contribution output through SRT or RTMP based on path quality.
- Distribution, recording, and analytics in platform services.
Recommended product path: Ingest and route, Player and embed, 24/7 streaming channels.
Configuration baseline that prevents common incidents
- Encoder profile: lock one tested profile per content class instead of changing per event.
- GOP policy: keep keyframe interval aligned with platform packaging needs.
- Bitrate guardrails: set min and max boundaries by network budget, not guesswork.
- Audio policy: standardize sample rate, channel layout, and loudness target.
- Scene hygiene: avoid heavy live effects that spike CPU during critical segments.
Protocol choice: when to use SRT vs RTMP
Use SRT when packet loss and route variance are expected, especially for field contribution and unstable uplinks. Use RTMP for legacy endpoints and simple controlled environments. In mixed environments, run SRT for ingest reliability and bridge to required destination protocols in the distribution layer.
Operational checklist before every event
- Run a 10 to 15 minute preflight with real scene complexity.
- Validate sustained encoder load and thermal behavior.
- Confirm contribution path RTT and packet loss thresholds.
- Verify backup output and failover handoff behavior.
- Check monitoring dashboards and alert routing ownership.
How to reduce latency without breaking stability
Do not chase minimum latency by shrinking every buffer. Reduce latency in measured increments while tracking frame drops, retransmission pressure, and player rebuffer events. Latency that looks good in one path can degrade quality under congestion if guardrails are absent.
Failure patterns and practical fixes
- Symptom: bitrate oscillation and visual pumping.
Fix: tighten encoder preset policy and avoid over-aggressive scene complexity. - Symptom: intermittent audio drift after scene switches.
Fix: normalize audio source chain and pin sample rate. - Symptom: one destination fails and takes entire show path down.
Fix: isolate fanout in routing layer and protect ingest session.
Team model for predictable OBS operations
Assign clear owners for scene design, encoder policy, and incident response. Keep a versioned configuration repository and avoid ad hoc edits minutes before going live. Small process discipline eliminates most recurring OBS incidents.
Use the bitrate calculator to size the workload, or build your own licence with Callaba Self-Hosted if the workflow needs more flexibility and infrastructure control. Managed launch is also available through AWS Marketplace.