Video Streaming Services
More live video workflow notes and product updates.
Choosing video streaming services is not a feature checklist exercise. For production teams, the right decision depends on delivery control, latency targets, monetization model, and integration depth. This guide provides an engineering-first framework to evaluate services and avoid expensive platform churn. For this workflow, 24/7 streaming channels is the most direct fit. Before full production rollout, run a Test and QA pass with Generate test videos and streaming quality check and video preview. Before full production rollout, run a Test and QA pass with a test app for end-to-end validation.
Use the bitrate calculator to size the workload, or build your own licence with Callaba Self-Hosted if the workflow needs more flexibility and infrastructure control. Managed launch is also available through AWS Marketplace.
Decision criteria that matter in production
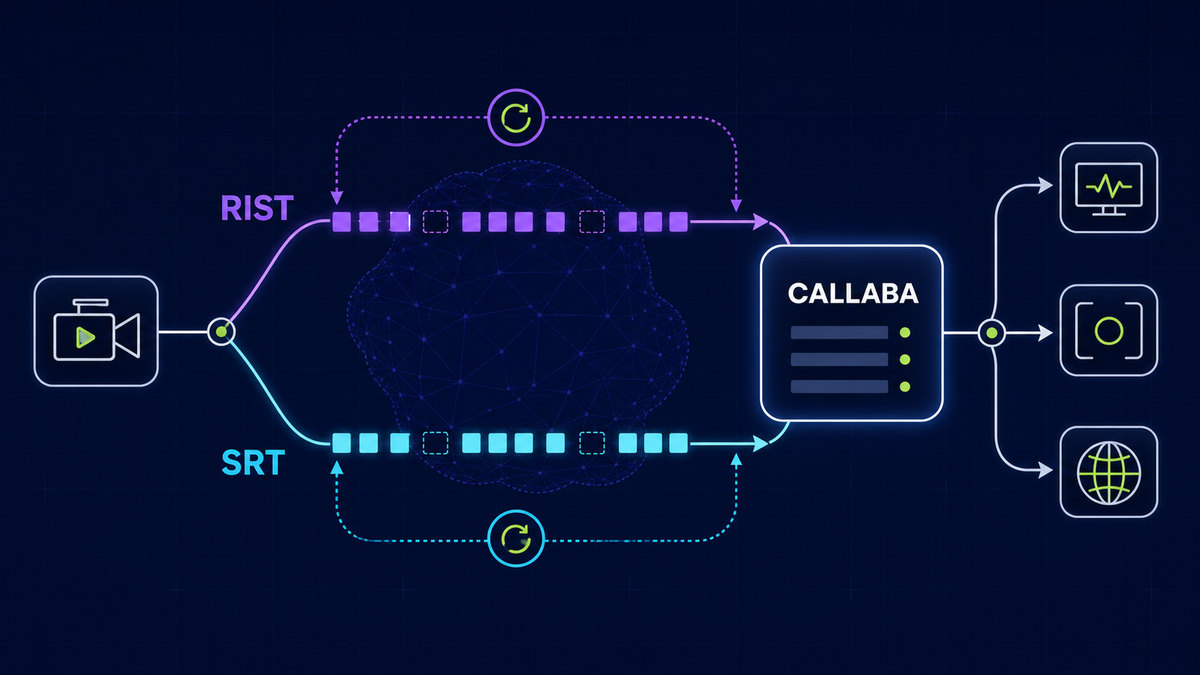
- Ingest reliability: stable contribution path under packet loss and route jitter.
- Playback control: player behavior, buffer policy, and analytics ownership.
- Access and monetization: paywall, authorization, and content policy support.
- Integration depth: API maturity, webhooks, provisioning automation.
- Cost predictability: transparent pricing under traffic spikes and growth scenarios.
Reference architecture for service evaluation
Run every candidate through the same architecture pattern: controlled ingest, standardized transcode ladder, representative player session load, and access enforcement flows. This isolates platform differences and prevents subjective selection by UI impression.
Recommended product path: Video platform API, Player and embed, Paywall and access.
Evaluation matrix you can execute in one week
- Define three target scenarios: low-latency event, VOD replay, gated access stream.
- Set quality SLOs and error budgets for each scenario.
- Run identical test assets and traffic envelopes across candidates.
- Collect ingest, transcode, playback, and support metrics.
- Score candidates by measurable outcome, not sales positioning.
Latency and quality tradeoff management
A service that advertises low latency may still fail your quality targets during network stress. Evaluate both median and tail behavior. Include startup latency, rebuffer rate, rendition stability, and recovery time after packet loss events. Tail performance is where customer trust is won or lost.
Security and policy readiness
Check authorization patterns, token lifecycle controls, DRM compatibility requirements, and audit visibility. Security features are often listed broadly but differ significantly in operational usability. Ask how quickly your team can rotate keys, revoke access, and investigate abuse events.
Migration risk assessment
- Estimate effort to migrate player integrations and analytics dashboards.
- Quantify content relocation and format compatibility risk.
- Model rollback strategy if production KPIs degrade after cutover.
Include migration cost in platform score. A cheaper hourly service can still be more expensive if migration overhead is high.
During migration planning, define coexistence period rules. Many teams need old and new services running in parallel for a limited time. Without clear cutover gates, this phase can become permanent and expensive. Set objective criteria for decommissioning old paths and track them weekly.
Common anti-patterns
- Anti-pattern: selecting by headline bitrate limits only.
Fix: test end-to-end session quality and operational tooling. - Anti-pattern: ignoring API constraints until automation phase.
Fix: require provisioning and monitoring API tests up front. - Anti-pattern: no ownership model for platform operations.
Fix: assign clear service owner and incident accountability.
Operational rollout plan
- Pilot one non-critical stream class first.
- Measure against baseline KPIs for two full release cycles.
- Expand to monetized workflows after quality and support stability.
- Document incident playbooks and dashboard ownership.
Keep one escalation path for service incidents across engineering, support, and customer teams. Fragmented escalation chains slow remediation and create conflicting communication. A single command channel with clear authority improves both MTTR and customer trust during visible incidents.
Related implementation guides
Continue with platform comparison, hosting options, service architecture patterns, and HLS deployment guidance.