HLS streaming in production: architecture, latency, and scaling guide
More live video workflow notes and product updates.
What HLS streaming means in production
- What to do: Treat HLS as a system: encoder settings, packaging (CMAF vs TS), ABR ladder, origin behavior, CDN configuration, player buffer tuning, and telemetry must be designed together.
- Why this works: HLS decouples encoding from delivery and client adaptation. Properly aligned segmentization and keyframe placement keep ABR switching smooth and predictable across hundreds of CDNs and device types.
- Where it breaks: Mismatched keyframes vs segments, aggressive low-latency settings on unsupported CDNs, and missing player ABR tuning cause stalls, bitrate oscillation, and startup delay spikes.
- How to detect & fix: Monitor manifest fetch timing, segment arrival times, rebuffer rate, and player ABR events. Fix by aligning GOP/keyframe with segment boundaries, increasing part/segment duration to reduce overhead, or falling back to standard HLS if CDN/players don’t handle chunked CMAF.
Decision guide: standard HLS vs low-latency HLS
- What to do: Choose standard HLS for maximum compatibility and lower origin pressure; choose LL‑HLS (CMAF chunked) for sub-5s live latency when you control packaging, CDN, and player stacks.
- Why this works: Standard HLS (2–6s segments) is cache-friendly and stable. LL‑HLS reduces inter-segment wait time by delivering parts (typically 200–500ms) and using the preload/push model, cutting the playlist wait factor.
- Where it breaks: LL‑HLS adds origin and CDN complexity: smaller parts increase HTTP request rate, reduce cache hit efficiency, and some CDNs do not support range- or chunked-transfer semantics required for parts. Use standard HLS when you expect heterogeneous device support or want predictable CDN caching behavior.
- How to detect & fix: Do an A/B test: measure startup time and rebuffer rate across devices. If LL‑HLS reduces latency but increases origin egress and rebuffer rates, either raise part duration to 300–500ms or use a packaging solution that assembles parts into cacheable segments at the origin.
End-to-end latency budget and architecture
Concrete budget example (target: 3–5s viewer latency):
- Encoder ingest (SRT): 120–400 ms (configurable latency buffer in encoder)
- Encoder encode and GOP/keyframe interval: 250–1000 ms per frame group; with 1s GOP add up to 1s
- Packaging (CMAF parts + manifest): 200–500 ms
- Origin + CDN propagation: 100–500 ms (depends on edge proximity and cache hit)
- Player gather/playout buffer & decoding: 300–800 ms
Total realistic LL‑HLS latency: 2–5s. For standard HLS with 6s segments and a 3-segment buffer, expect 12–20s.
- What to do: Budget per-hop latency and measure. If you aim for sub-5s, provision SRT ingest with small encoder latency, use CMAF parts (200–400ms), and keep player buffer target at 2–4s.
- Why this works: Breaking latency into accountable pieces lets you trade: increase encoder latency to reduce packet loss vs reduce part duration to decrease viewer latency.
- Where it breaks: High RTT to origin/CDN, small part sizes that overload origin, or player with poor ABR logic can blow budget.
- How to detect & fix: Add telemetry at ingress (SRT stats), origin packaging timestamps, CDN edge logs, and player-side timing (manifest fetch, first frame). Use /what-is-srt-statistics and /find-the-perfect-latency-for-your-srt-setup to calibrate SRT and encoder settings.
Implementation recipes that ship
Standard HLS for maximum compatibility
- What to do:
- Encode at a stable keyframe interval equal to or dividing your segment duration (common: segment=6s, keyframe=2s or 6s).
- Segment length: 4–6s for wide compatibility; use MPEG‑TS or CMAF packaged segments if targeted players support CMAF.
- ABR ladder example for 1080p60: 8000k (1080p60), 4500k (720p60), 2500k (720p30), 1500k (480p), 800k (360p), 350k (240p).
- Player target buffer: 10–25s; reduce to 6–10s for faster startup if network is stable.
- Why this works: Longer segments reduce HTTP requests and improve CDN cache hit ratio and origin egress efficiency.
- Where it breaks: Latency will be high (10–30s depending on playlist length). Also, ABR switching can be delayed if keyframes are misaligned with segment boundaries.
- How to detect & fix: If edges show high miss ratios, check your cache policy and ensure segment files are cacheable. If players stall on switching, verify GOP alignment and that segment boundaries include a keyframe.
- Product mapping: Use Video on Demand for VOD workflows and Video API for packaging and packaging automation for compatibility-oriented delivery.
Low-latency HLS (LL-HLS) over CMAF
- What to do:
- Target part durations of 200–500 ms (typical starting point: 250 ms).
- Use a keyframe interval aligned to part boundaries (1s GOP with 250 ms parts -> 4 parts per GOP or use 500 ms GOP with 250 ms parts depending on content).
- Produce a low-latency playlist with PART and PRELOAD-HINT tags and allow clients to request partial segments.
- Ensure packaging supports chunked transfer or origin-side assembly so CDN caching is not catastrophically degraded.
- Why this works: Smaller CMAF parts break one long wait (segment completion) into multiple short waits; combined with PRELOAD-HINT and HTTP/2 or HTTP/3, viewers can begin decoding earlier.
- Where it breaks: If the CDN doesn't support part requests or strips chunk metadata, you may see increased origin load and higher egress cost, or playback stalls on older devices that do not understand LL‑HLS.
- How to detect & fix: Monitor part request rates at the origin and CDN hit/miss headers. If origin egress grows unexpectedly, either increase part duration to 300–500 ms, enable origin-side segment assembly, or fallback to standard HLS for unsupported device groups. For documentation of player-side ABR considerations see adaptive bitrate player notes.
- Product mapping: Use Continuous Streaming packaging when you need persistent low-latency channels and automatic assembly at the origin.
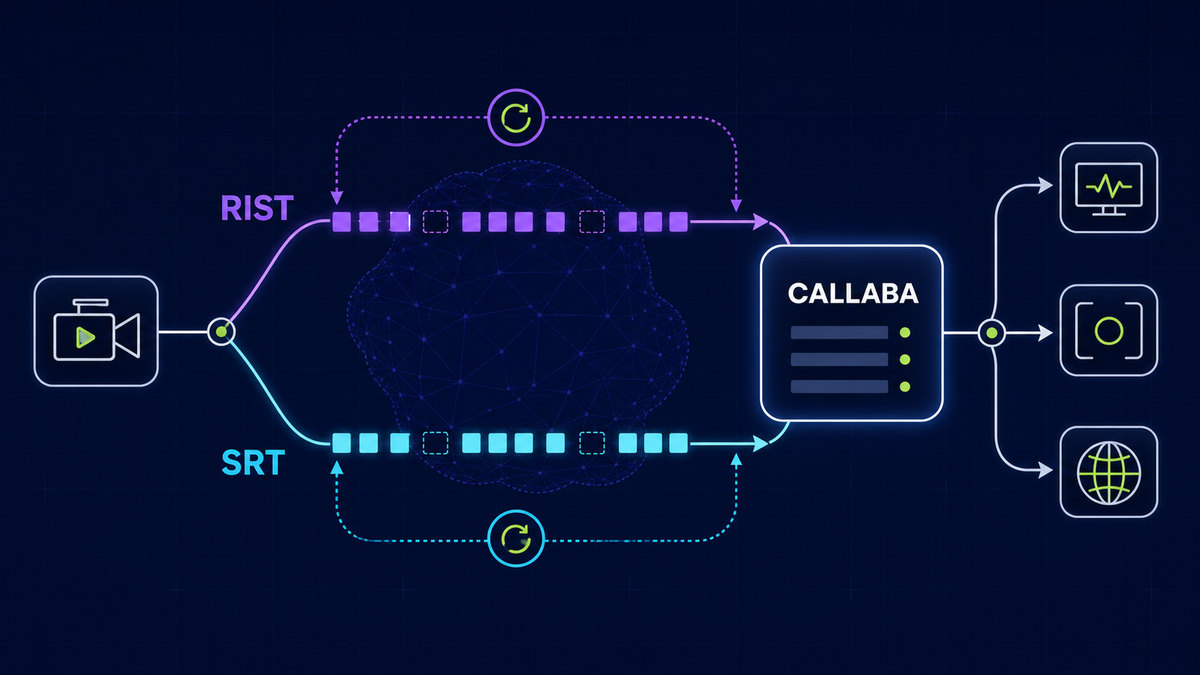
SRT ingest to HLS distribution pipeline
- What to do:
- Ingest with SRT, set encoder SRT latency to 120–400 ms depending on network volatility; enable link encryption as needed.
- At the edge, transcode or transrate to your ABR ladder, fragment into CMAF parts (250–400 ms), and publish to origin for CDN distribution.
- Emit SRT statistics to your monitoring stack for jitter, packet loss, and RTT tracking.
- Why this works: SRT gives you reliable, low-latency transport from encoders in the field to cloud ingest by compensating for packet loss and jitter without rebuffering the encoder-to-origin hop.
- Where it breaks: SRT only covers ingress. If your packaging or CDN doesn't support the low-latency primitives (chunked CMAF or LL‑HLS tags), the last‑mile viewer latency will still be large.
- How to detect & fix: Use /what-is-srt-protocol and /what-is-srt-statistics to interpret SRT metrics; if SRT reports high packet loss, increase latency setting or switch to alternate upstream networks. If packaged parts are not being consumed correctly by the CDN, assemble into cacheable segments at the origin or fall back to standard HLS.
- Product mapping: If you need a managed ingest pipeline with telemetry and repackage capabilities, evaluate Video API and Continuous Streaming to simplify SRT ingest, stats collection, and HLS/CMAF packaging.
Practical configuration targets
Use these as starting points; tune per event and network conditions.
- Encoder
- GOP/keyframe interval: 1s or equal to segment duration; never exceed segment duration.
- Encode bitrate ladder example (1080p60 live sport): 8000k, 4500k, 3000k, 1800k, 900k, 450k.
- HLS packaging
- Standard HLS segment duration: 4–6s (aim 6s for best CDN efficiency).
- LL‑HLS part duration: 200–500 ms (start at 250 ms), target 3–5s end-to-end.
- Playlist target: keep 3–5 parts ahead for LL‑HLS; 3 segments for standard playback.
- Player
- Startup buffer: LL‑HLS 1.5–4s; standard HLS 8–20s.
- Buffer depth: prefer 2–6s for LL; 15–30s for stable VOD/standard live.
- SRT
- Set SRT latency box: 120–600 ms depending on path jitter; use 300 ms for wide-field encoders with some packet loss. See how to pick SRT latency.
Limitations and trade-offs
- Scale & CDN cost: LL‑HLS increases request rate and can inflate origin egress. Trade lower latency against higher CDN and origin costs.
- Compatibility: Older devices and players may not support LL‑HLS; standard HLS ensures the broadest reach.
- DRM & SSAI complexity: Chunked CMAF and part-level encryption complicate DRM workflows and server-side ad insertion. You may need server-side assembly or specialized SSAI integrations.
- Operational complexity: LL‑HLS requires more sophisticated monitoring and a packaging layer that understands PART/PRELOAD tags; this increases engineering and QA effort.
- How to accept trade-offs: Quantify cost per second of latency reduction. If each second saved costs more than the business value of lower latency, prefer simpler standard HLS.
Common mistakes and how to fix them
- Mistake: Keyframe interval not aligned with segment/part boundaries.
- Detect: Abrupt black frames or delays on ABR switch, player event logs showing failed segment decode.
- Fix: Set encoder GOP to match segment length (e.g., 2s GOP for 2s segments) or use 1s GOP for LL‑HLS with 250 ms parts. Rollback-safe fix: repackage manifests to use previous segment durations and force clients to use primary rendition.
- Mistake: Turning on LL‑HLS without CDN support.
- Detect: Spikes in origin traffic; player stalls for some geographic regions; CDN x-cache headers show misses.
- Fix: Coordinate with CDN for chunked transfer support or assemble parts into larger cacheable segments at origin. Rollback-safe: revert to standard HLS manifests and advertise the fallback playlist to players.
- Mistake: Too-small part durations (<100 ms) to chase ultra-low latency.
- Detect: High CPU/memory on packagers; high HTTP request latency; ABR instability.
- Fix: Increase part duration to 200–400 ms. Rollback-safe: switch to a standard 4–6s segment window temporarily.
- Mistake: No SRT telemetry or default SRT latency in the encoder.
- Detect: Unexpected rebuffering between encoder and origin despite low network load.
- Fix: Enable SRT stats and adjust the SRT latency parameter. Read what is SRT and the SRT stats guide for tuning.
Rollout checklist
- Create a staging pipeline that mirrors production: SRT ingest -> transcode -> packaging -> origin -> CDN edge.
- Test both standard HLS and LL‑HLS with a controlled audience and measure startup time, rebuffer rate, bitrate switches, and CDN egress.
- Target rebuffer rate: <1% for premium streams; <0.5% for linear broadcast.
- Validate keyframe alignment, GOP settings, and part/segment durations across encoders.
- Confirm CDN supports HTTP/2 or HTTP/3 and chunked transfers; if using AWS CloudFront, follow CloudFront setup notes for live origin configuration.
- Ensure player ABR behavior is tuned; review player adaptive bitrate guidance and test under throttled network profiles.
- Prepare fallbacks: standard HLS playlist and a plan to switch CDNs or assembly rules if origin or CDN misbehaves.
- Instrument telemetry: ingest SRT stats, packaging latency, CDN x-cache, origin CPU, and player-side metrics. Integrate with alerting for rebuffer rate and manifest fetch failures.
Example architectures
- Small webcast (1k concurrent viewers)
Flow: SRT ingest -> single transcoder (autoscaled) -> HLS packaging (6s segments) -> CDN. Numbers: 1 source @ 6 Mbps ingest; transcoded outputs total 12 Mbps egress to origin; CDN egress roughly 6 Mbps * 1000 viewers = 6 Gbps (peaked to higher depending on ABR selection). Use Video API to automate packaging and ABR ladder generation. Before full production rollout, run a Test and QA pass with Generate test videos and a test app for end-to-end validation.
- Large live sports (100k viewers, target latency 3–5s)
Flow: multiple SRT ingest points -> geo‑distributed transcoder fleet -> centralized packaging with CMAF parts -> origin assembly + multi‑CDN with geo-routing. Numbers: 6 input bitrates per viewer; average viewer bitrate 2.5 Mbps -> total CDN egress ~250 Gbps peak. Expect origin egress to rise if LL‑HLS parts are not assembled at the origin; mitigate with origin-side assembly and multi-CDN offload. Review our architecture patterns and integrate with Continuous Streaming for persistent low-latency channels.
- Pay-per-view event with DRM and SSAI
Flow: SRT ingest -> packager with encrypted CMAF -> DRM license server -> SSAI insertion (server-side), then CDN. Notes: DRM integration with LL‑HLS adds complexity at the part level; use the Pay‑Per‑View product for billing and DRM orchestration and consult API docs for integration points.
Troubleshooting quick wins
- High startup latency: If startup > expected, check segment duration and playlist window. Quick fix: serve a smaller bootstrap playlist (reduce required segments to start) or temporarily reduce segment duration from 6s to 4s in packaging.
- Rebuffers on poor networks: Check ABR ladder and initial bitrate. Quick fix: lower the lowest rendition to 150–250 kbps and make it the startup rendition to avoid initial stalls.
- Unstable ABR switches: Verify keyframe alignment and players’ ABR thresholds. Quick fix: align keyframes to segment boundaries and increase player switch hysteresis (avoid switching for small bandwidth dips).
- Origin bandwidth spike after enabling LL‑HLS: Use origin-side assembly or increase part duration to 300–500 ms. Measure with CDN x-cache header and origin logs.
- SRT jitter or packet loss: Increase encoder SRT latency by +200 ms and re-run tests. Consult SRT statistics to validate the change.
Next step
Immediate implementation actions you can take today:
- Run a staged test: spin up SRT ingest and package two parallel outputs — standard HLS (6s segments) and LL‑HLS (250 ms parts). Measure startup, rebuffer rate, and origin egress for 30 minutes of representative content.
- If you need managed packaging or a faster path to production, evaluate Continuous Streaming for persistent low-latency channels and Video API for programmatic packaging and ABR automation.
- For monetized events, provision a paywall and DRM with Pay‑Per‑View and verify DRM across players using the API reference at the engine docs.
- Instrument SRT ingest metrics and run a short network-limited test to pick an SRT latency (start at 300 ms), using our SRT latency guide as calibration.
If you want help implementing these steps or need a production review of latency vs cost trade-offs, start a trial or contact our engineering team via the Video API page to schedule a workshop.
See also How And Why Should You Set Up Subtitles And Closed Captions Cc.
Use the bitrate calculator to size the workload, or build your own licence with Callaba Self-Hosted if the workflow needs more flexibility and infrastructure control. Managed launch is also available through AWS Marketplace.
Use the calculator for traffic scenarios, compare cloud launch speed via AWS Marketplace, and keep a self hosted path for fixed-cost planning and compliance-heavy deployments.