HLS: Practical Guide for Real Streaming Delivery
More live video workflow notes and product updates.
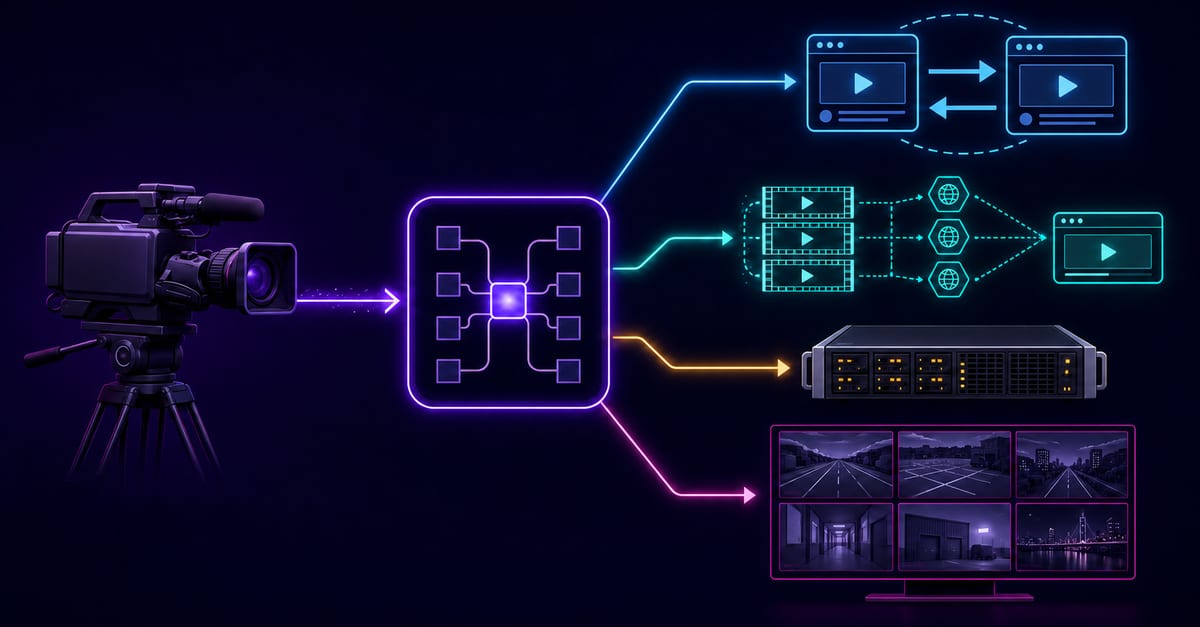
HLS is one of the most common delivery protocols for live and VOD playback on the public internet. In practical terms, teams choose HLS because it scales well, works across many devices, and fits CDN-based distribution. The key tradeoff is simple: HLS usually gives strong compatibility and reliability, but not the lowest possible interaction latency. For this workflow, Player & embed is the most direct fit.
If you search for “HLS,” most people need quick answers: what HLS is today, when to choose it, how to configure it without quality regressions, and where it should be combined with other protocols. This guide focuses exactly on that.
What HLS Is Today
- Primary role: scalable HTTP-based streaming delivery.
- Best fit: broad device support and stable large-audience playback.
- Common model: adaptive bitrate variants delivered through CDN.
- Main limitation: not ideal as a pure solution for ultra-interactive real-time flows.
For core implementation background, use HLS streaming and HLS player.
How HLS Works in Production Pipelines
A typical HLS path includes ingest, transcoding/profile ladder generation, segment and manifest production, CDN caching, and player adaptation. HLS quality outcomes depend on the full chain, not just one player setting.
In stable systems, teams control three things:
- Predictable variant ladder design.
- Consistent segment and manifest behavior.
- Cache policy tuned for startup and continuity.
If one of these is weak, users experience slow startup, unnecessary buffering, or unstable quality switching.
When to Choose HLS
- Large one-to-many audiences across mixed client devices.
- Need for mature CDN integration and cache control.
- Content programs where continuity and compatibility outrank interaction latency.
- VOD + live hybrid workflows with shared player stack.
When Not to Use HLS Alone
- Highly interactive sessions where sub-second response is mandatory.
- Remote contribution paths with unstable internet where transport resilience is primary risk.
- Workflows that need direct two-way conversational real-time behavior.
In those cases, teams often combine HLS with other protocol layers, for example SRT contribution or WebRTC interaction branches.
HLS vs MP4 (Common Confusion)
HLS is a delivery protocol and packaging model. MP4 is a container format. In real workflows, HLS can deliver media packaged from MP4 assets, but they are not interchangeable concepts. A practical comparison reference: why HLS is better than MP4.
Simple rule: if your requirement is adaptive streaming over variable networks, HLS-style delivery is usually more suitable than serving one fixed MP4 rendition.
HLS Player Strategy
Player behavior is where user experience becomes visible. Your player should handle startup logic, variant switching, and buffer policy in a predictable way across device classes. Relevant references: HLS player, M3U8 player, adaptive bitrate HLS player.
Player checklist
- Startup target measured by device and region.
- Variant switching without visible oscillation.
- Recovery behavior after transient CDN/network degradation.
- Consistent autoplay and embed policy handling.
CDN and Caching Reality
HLS reliability heavily depends on edge behavior. Wrong cache strategy can hurt startup and continuity even when origin and encoder look healthy. Use this practical reference: caching video fragments for HLS CloudFront CDN setup.
Practical guidance:
- Cache manifests and segments with policy aligned to update cadence.
- Validate edge behavior across at least two regions.
- Correlate player telemetry with CDN windows before tuning profile ladder.
- Avoid broad cache policy changes during high-impact live windows.
HLS and Low-Latency Expectations
HLS can be optimized for lower latency than legacy defaults, but teams should avoid promising “instant” interactivity if architecture is still broadcast-oriented. For contribution-heavy low-latency pipelines, compare with resilient transport models such as low latency video via SRT and decision context in SRT vs RTMP.
Best practice: set explicit latency and continuity targets per event class, then tune one layer at a time. Do not retune encoder, CDN, and player simultaneously.
HLS Workflow for Live Teams
Use a fixed sequence:
- Preflight: source readiness, ladder profile selection, player target check.
- Warmup: private stream with full scene and graphics load.
- Go-live: freeze non-critical changes.
- Recovery: apply approved fallback profile or rung strategy first.
- Review: record first-failure signal and one process improvement.
This routine is intentionally simple. It reduces incident time better than complex ad-hoc tuning.
Reference Architectures
Architecture A: Standard HLS delivery stack
Ingest to processing, produce HLS variants, distribute through CDN, play via controlled embed/player. Strong default for broad compatibility and predictable operations.
Architecture B: Hybrid contribution + HLS delivery
Use resilient contribution transport for unstable uplinks, then publish through HLS delivery for audience scale. This pattern isolates transport risk from playback compatibility goals.
Architecture C: Product-led automation path
Automate lifecycle and profile controls for recurring events to reduce manual drift and repeated errors.
Hands-On Troubleshooting
Problem: startup is slow even with good bitrate
Check manifest behavior, edge cache freshness, and player startup policy before changing ladder values.
Problem: frequent quality switching
Inspect variant spacing, segment stability, and player adaptation aggressiveness. Tight rung spacing or unstable throughput windows can cause oscillation.
Problem: buffering spikes at peak traffic
Correlate CDN region behavior with player logs in the same timestamp window. Apply fallback rung policy first, then retest.
Problem: mobile users report worse continuity
Test with cohort-specific conditions and review startup profile for mobile constraints. Do not apply desktop assumptions globally.
Quick Operational Rules
- One approved ladder per event class.
- One fallback rung strategy with named owner.
- One preflight checklist for every live window.
- One post-run review note with one required improvement.
These rules are enough to remove many recurring HLS quality incidents.
KPI Set That Helps Decisions
- Startup success under threshold.
- Continuity quality (rebuffer ratio and interruption duration).
- Recovery time after degradation.
- Operator response time to confirmed mitigation.
Internal Product Mapping
For implementation progression:
Use the bitrate calculator to size the workload, or build your own licence with Callaba Self-Hosted if the workflow needs more flexibility and infrastructure control. Managed launch is also available through AWS Marketplace.
For infrastructure-control planning, evaluate self hosted streaming solution. For cloud launch and procurement speed, compare the AWS Marketplace listing.
FAQ
Is HLS still the default choice for large-scale playback?
In many workflows, yes. It remains a strong choice for broad compatibility and CDN-based scale.
Is HLS good for real-time interactive apps?
Not usually as a standalone approach. Highly interactive scenarios often need WebRTC-like paths.
What causes most HLS quality failures?
Usually a combination of ladder design, cache policy, and player adaptation behavior rather than one single misconfigured value.
How do I improve HLS reliability quickly?
Standardize ladder profiles, run consistent preflight tests, and enforce one fallback policy with clear ownership.
Next Step
Pick one real stream, apply this HLS checklist, and promote only settings that reduce continuity variance over full-session tests. Reliable HLS operations come from disciplined iteration, not one-time aggressive tuning.
Practical Note for Teams
Most HLS incidents are process failures disguised as technical complexity. Keep runbooks short, ownership clear, and rollout changes incremental. That is the fastest path to stable outcomes for both technical and non-technical operators.
5-Minute Sanity Check Before Go-Live
Before every important session: verify chosen ladder, validate startup from at least one mobile and one desktop client, trigger one heavy scene transition in warmup, confirm fallback rung ownership, and check a second-region playback probe. This quick routine catches hidden issues before audience impact.
Detailed Ladder Design Guidance
Ladder design is one of the biggest practical drivers of HLS quality. A ladder that looks good in a spreadsheet can still fail in real sessions if rung spacing and bitrate assumptions do not match audience network behavior. Start from conservative profiles, then tune by event class and viewer telemetry.
- Conservative rung: protects continuity for constrained networks.
- Standard rung: balances clarity and stability for normal conditions.
- High rung: improves detail where headroom exists.
Do not over-pack ladders with tiny rung differences. Too many similar variants can increase unstable switching without meaningful visual benefit. Keep each rung purposeful and measurable in post-run analysis.
Event-Class Profile Mapping
Use different HLS profile defaults for different event types:
- Education and webinars: prioritize speech clarity and continuity.
- Sports and fast motion: prioritize motion stability and controlled fallback.
- Commerce and launches: prioritize continuity during conversion windows.
- 24/7 channels: prioritize repeatability and low-maintenance operation.
One profile for all events is a common reason quality drifts and support load spikes.
Player Adaptation Policy
Adaptation logic should avoid panic switching. If your player jumps too aggressively between variants, users see unstable quality. If it is too slow, users see unnecessary buffering. Treat adaptation policy as a controlled setting with clear owner and release cycle.
Practical checks:
- Measure time to first stable variant after startup.
- Count excessive variant switches per session cohort.
- Compare switch behavior before and after policy edits.
- Rollback quickly if continuity worsens.
Multi-Region Validation
HLS behavior can vary significantly across regions due to edge route and cache conditions. Validate key regions before promotion, especially for high-impact events. Teams often overfit to one region and then discover instability at launch time.
- Run startup checks from at least two regions.
- Compare continuity metrics in the same event window.
- Record region-specific anomalies in one timeline.
- Apply targeted fixes before global policy changes.
Operational Ownership Model
HLS reliability improves when responsibilities are explicit:
- Encoding owner: profile ladder and packaging health.
- Delivery owner: CDN and cache behavior.
- Playback owner: player startup and adaptation policy.
- Incident owner: fallback decision and comms timing.
Without ownership, teams spend more time debating causes than restoring service.
Failure Pattern Library
Pattern A: Good lab results, poor peak-hour behavior
Usually a cache and concurrency issue, not a codec issue. Validate edge behavior under realistic traffic envelopes.
Pattern B: Stable desktop, unstable mobile
Usually adaptation and startup assumptions tuned to desktop bandwidth patterns. Build separate mobile-focused validation checks.
Pattern C: Frequent quality drops after scene transitions
Often tied to transient source/encode spikes. Reduce transition pressure and verify encoder headroom before retuning delivery settings.
Pattern D: Repeat incidents after “successful” fixes
Usually process failure: no durable runbook update or no ownership for the changed setting.
Deployment Checklist Before Promotion
- Rehearse with real overlays, graphics, and audio chain.
- Validate startup and continuity across key cohorts.
- Test fallback rung action and recovery timing.
- Freeze non-critical changes before event window.
- Assign incident owner and escalation path.
This checklist is short on purpose. Teams actually use short checklists.
Post-Run Review Template
- What was the first user-visible symptom?
- Which metric confirmed the issue fastest?
- Which fallback action was applied first?
- How long to restore healthy continuity?
- What one rule changes before next stream?
Repeat this review after every significant stream. Consistency beats occasional major redesigns.
Team Onboarding Notes
New operators should not learn HLS from scattered docs. Give them one practical onboarding pack: profile ladder map, player policy summary, preflight card, fallback procedure, and post-run template. This reduces avoidable mistakes and improves handover quality between shifts.
Run short drills regularly: one startup failure drill, one continuity recovery drill, and one fallback ownership drill. These exercises reduce reaction delay during real incidents.